

[ 문자열 처리 메서드 ]
문자열 생성
string str = new string('s', 7);
Console.WriteLine(str);
//출력결과
sssssssnew 키워드를 사용해서 char 문자와 개수를 지정하면 생성할 수 있다.
분할
string str = "Hello, World!";
string[] split = str.Split(", ");
Console.WriteLine(split[0]);
Console.WriteLine(split[1]);
//출력결과
Hello
World!Split()은 괄호 안의 값을 기준으로 나누는 것이다.
※ 주의할 점
ⓛ 나눈 값을 할당할 변수는 대괄호를 붙여서 배열로 생성해야 한다.
② 출력할 때 나눈 값들을 보고 싶다면 인덱싱을 이용해야 한다.
③ 나누는 기준이 되는 문자가 1개라면 ' ', 2개 이상이라면 " "를 사용한다.
대체
string str = "Hello, World!";
string replace = str.Replace("World", "Seoyeong");
Console.WriteLine(replace);
//출력결과
Hello, Seoyeong!Replace() 함수를 사용해서 앞의 값을 뒤의 값으로 바꿀 수 있다.
검색
string str = "Hello, World!";
int index = str.IndexOf("World");
Console.WriteLine(index);
//출력결과
7IndexOf() 함수는 입력한 값이 맨 처음으로 나오는 인덱스 값을 반환한다.
0부터 세기 시작해서 특수문자, 띄어쓰기 모두 포함한다. World가 처음으로 등장하는 위치는 인덱스 7에 위치라서 7을 출력한다.
변환
1) 숫자 → 문자
int num = 55;
string str = num.ToString();
Console.WriteLine(str);
Console.WriteLine(str.GetType());
//출력결과
55
System.String변수명.ToString()을 사용하면 숫자 타입을 문자열로 바꿀 수 있다. GetType()을 이용해서 타입을 확인했을 때, String 타입인 것을 볼 수 있다. int 타입 외에도 다른 타입도 문자열로 바꿀 수 있다.
2) 문자 → 숫자
string str = "100";
int num = int.Parse(str);
Console.WriteLine(num);
Console.WriteLine(num.GetType());
//출력결과
100
System.Int32int.Parse()를 활용하면 숫자 형태의 문자열을 int 타입으로 변환할 수 있다. GetType()을 이용해서 타입을 확인했을 때, Int 타입인 것을 볼 수 있다.
int 외에도 다른 float, long 등 숫자값을 갖는 다른 타입으로도 변환할 수 있다. 하지만 문자열에서의 숫자가 실수라면, 정수로 변환할 수 없다. 예를 들어 str에 "100.343"과 같은 실수 값이 들어있었다면, int로 변환할 수 없다. 대신 float를 사용해야 한다.
포맷팅
1) 문자열 형식화
string name = "김서영";
int age = 22;
string sentence = string.Format("제 이름은 {0}이고, 나이는 {1}살 입니다.", name, age);
Console.WriteLine(sentence);
//출력결과
제 이름은 김서영이고, 나이는 22살 입니다.자료형.Format("문장~ {인덱스} ", 변수명)의 형태이다. 문자열 안에 중괄호와 인덱스 번호를 쓰고, 뒤에 불러오려는 변수명을 입력한다. 위 코드에서 인덱스 0은 name 변수이고, 인덱스 1은 age 변수이다.
2) 문자열 보간
string name = "김서영";
int age = 22;
string sentence = $"제 이름은 {name}이고, 나이는 {age}살 입니다.";
Console.WriteLine(sentence);
//출력결과
제 이름은 김서영이고, 나이는 22살 입니다.인덱스를 사용하지 않고, 중괄호 내에 직접적으로 변수명을 입력한다. Format()처럼 함수가 아니기 때문에 소괄호는 삭제하고, 앞에 $ 특수문자를 입력한다.
[ 배열 ]
동일한 자료형의 값들이 연속으로 저장된 구조이다. 인덱스를 이용해서 원하는 요소에 접근이 가능하다.
초기화할 때 선언했던 크기만큼 메모리가 할당되며, 나중에 늘리거나 줄이는 것과 같은 수정이 불가능하다.
1차원 배열
int[] num; //선언
num = new int[3]; //초기화
int[] num = new int[3]; //선언 및 초기화
num[1] = 20; //접근1
age = num[1]; //접근2선언: 자료형[] 배열명;
초기화: 배열명 = new 자료형[크기];
선언 및 초기화: 자료형[] 배열명 = new 자료형[크기];
접근1: 배열명[인덱스] = 값;
접근2: 변수명 = 배열명[인덱스];
int[] num = {10, 20, 30};배열을 선언하자마자 데이터 값을 초기화하려면 중괄호 안에 값을 입력하면 되고, 배열의 크기도 따로 지정하지 않아도 된다.
다차원 배열
int[,] array = new int[3,2]; //3행 2열 2차원 배열 선언 및 초기화
array[0,0] = 1; //요소 할당
array[1,0] = 2;
array[2,0] = 3;
array[0,1] = 4;
array[1,1] = 5;
array[2,1] = 6;
int[,] array = new int[3, 2] { { 1, 2}, { 3, 4 }, { 5, 6 } }; //배열 선언 및 요소 초기화1차원 배열이 여러 개로 묶여 있는 것이다. 행과 열로 이루어져 있으며 2차원과 3차원 배열 등이 있다.
[ 컬렉션 ]
배열과 유사하게 자료를 모아놓은 구조이지만, 크기를 변경할 수 있다.
컬렉션을 사용하기 위해서는 System.Collections.Generic 네임스페이스를 추가해야 하고 다양한 컬렉션이 존재한다.
리스트(List)
List<자료형> 리스트명 = new List<자료형>();리스트는 가변적인 크기를 갖기 때문에 크기를 따로 지정하지 않는다. 따라서 요소들을 셀 때 length 대신 count를 사용한다.
데이터를 추가할 때는 리스트명.Add();를 사용해서 리스트의 끝에 요소를 추가한다. 크기가 정해지지 않았기 때문에 인덱스 없이 바로 데이터 값을 입력하면 된다.
데이터를 제거할 때는 리스트명.Remove();를 사용해서 입력된 특정 요솟값을 제거한다. 또는 이미 추가된 요소 내의 인덱스를 이용해서 제거할 수도 있다.
인덱스는 요소가 추가된 순서대로 할당된다. 요솟값이 제거되면 그에 영향을 받는 일부 인덱스도 변경된다.
딕셔너리(Dictionary)
Dictionary<키_자료형, 값_자료형> 딕셔너리명 = new Dictionary<키_자료형, 값_자료형>();키(key)와 값(value)의 쌍이 저장된 구조이다. 딕셔너리에서는 중복된 키를 가질 수 없다.
딕셔너리명.Add(키, 값);를 이용해서 데이터를 추가하고, 딕셔너리명.Remove(키);를 이용해서 데이터를 제거할 수 있다.
딕셔너리의 모든 키-값 쌍을 불러오려면 KeyValuePare<키_자료형, 값_자료형>을 사용한다.
스택(Stack)
Stack<자료형> 스택명 = new Stack<자료형>();후입선출의 구조를 가지고 있다. 아래에서부터 위로 데이터를 쌓는다. 데이터를 뺄 때는 위에서부터, 즉 나중에 들어온 데이터부터 빼낸다.
데이터를 추가할 때는 Push() 함수를 사용하고, Pop() 함수를 이용해서 데이터를 뺄 때는 제일 나중에 추가된 데이터가 출력된다.
큐(Queue)
Queue<자료형> 큐명 = new Queue<자료형>();선입선출의 구조를 가지고 있다. 데이터가 추가된 순서대로 처리된다.
데이터를 추가할 때는 EnQueue() 함수를 사용하고, 데이터를 뺄 때는 Dequeue() 함수를 사용하며 제일 먼저 들어간 데이터가 가장 먼저 나온다.
해시셋(HashSet)
HashSet<자료형> 해시셋명 = new HashSet<자료형>();리스트와 유사하지만 중복되지 않은 요소들로 구성되어 있다.
그렇다면 배열 대신 리스트를 사용하면 되는 것이 아닌가?
리스트는 배열보다 메모리를 더 많이 사용한다. 그리고 인덱싱이 불가능하기 때문에 데이터를 접근하는 데 시간이 더 소요되고, 리스트는 코드가 더 길어지기 때문에 가독성과 유지보수가 어려워진다.
따라서 배열과 리스트 중 사용할 데이터 구조를 선택할 때, 데이터 크기와 사용 목적을 고려하여 적절한 것으로 선택해야 한다.
[ 메서드 ]
개념
접근제한자 자료형 변수명 () {}일련의 코드들을 하나로 묶어놓은 집합이다. 괄호 유무가 함수를 결정한다. 소괄호는 반드시 있어야 하고, 중괄호는 한 줄이면 생략 가능하다.
- 소괄호: 값을 받는 역할(입력받을 데이터)
- 중괄호: 받은 값으로 연산을 하는 역할(실제 로직)
자료형은 반환값의 타입을 의미한다. int라면 정수형 값을 반환한다. void는 반환값이 없어서 아무것도 반환하지 않는다.
기본적으로 int, float와 같은 자료형은 반환값이 있기 때문에 return을 사용해야 하며, 없으면 에러가 발생한다.
하지만 void는 반환값이 없기 때문에 return이 없어도 된다. void에서의 return은 따로 반환값이 있는 게 아니라, 그 즉시 함수가 종료되면서 밑의 로직이 더 이상 실행되지 않는 것이다. 함수를 호출했던 위치로 돌아가서 그다음 줄을 실행한다.
return 값으로 클래스도 반환할 수 있다. 클래스를 반환하는 경우에는 해당 클래스 내부에 있는 코드들도 전부 가져온다.
반환 값이 있으면 외부에서 그 값을 받아서 활용할 수 있다.
public으로 변수에 직접 접근할 수 있지 않나?
그 방법을 지양하는 이유는 보안 상의 문제와, 여러 곳에서 해당 변수를 동시에 사용할 경우 적시에 원하는 값을 못 가져올 수 있기 때문이다.
메서드를 이용해서 반복되는 코드를 다시 작성하지 않아도 되고, 코드의 관리와 유지보수가 편리해진다. 또한 메서드 단위로 행동을 정의하고 메서드 이름을 입력함으로써 전체 코드 구조를 이해하기 쉬워진다.
메서드 오버로딩
void print(string name);
void print(int age);메서드 오버로딩은 메서드명은 같지만, 매개변수의 개수, 타입, 순서가 다른 것이다.
메서드 오버로딩을 할 때는 매개변수만 다르면 서로 다른 메서드로 인식을 하며, 반환값 타입은 고려하지 않는다.
재귀 호출
static void Main(string[] args)
{
CountUp(20);
}
static void CountUp(int n)
{
if (n >= 22)
{
Console.WriteLine("Finish");
}
else
{
Console.WriteLine(n);
CountUp(n + 1);
}
}
//출력결과
20
21
Finish재귀 호출은 메서드가 자기 자신을 호출하는 것이다. 재귀 호출을 하면 호출 스택에 메서드를 쌓고, 반환될 때 쌓인 메서드를 제거해서 호출 됐던 곳으로 다시 돌아간다. 자칫 무한 루프를 발생시킬 수 있으므로 주의해야 한다.
[ 구조체 ]
static void Main(string[] args)
{
Coffee today;
today.menu = "캬라멜마끼아또";
today.count = 3;
today.Print();
}
struct Coffee
{
public string menu;
public int count;
public void Print()
{
Console.WriteLine($"오늘은 {menu}를 {count}잔 마셨습니다.");
}
}
//출력결과
오늘은 캬라멜마끼아또를 3잔 마셨습니다.구조체는 사용자가 정의한 일련의 코드 집합으로, struct 키워드를 이용해서 생성한다.
- 멤버 변수: 필드
- 멤버 함수: 메서드
구조체는 구조체명 변수명;으로 변수를 선언하고, 이 변수에 접근함으로써 구조체 내의 코드를 실행한다.
접근할 때에는 변수명.필드명 = 값; 또는 변수명.메서드명();으로 호출할 수 있다.
[조건문]
2024.04.03 - [Coding/C#] - C# 조건문 if, else if, else, switch case, 조건부 논리 연산자
조건문에 대한 기초적인 내용은 위 게시글에서도 확인할 수 있다.
if문
if문은 조건이 많이 붙을 때 사용하기 좋다.
else는 조건을 만족하지 않은 모든 경우에 실행되기 때문에, 조건을 작성하지 않는다
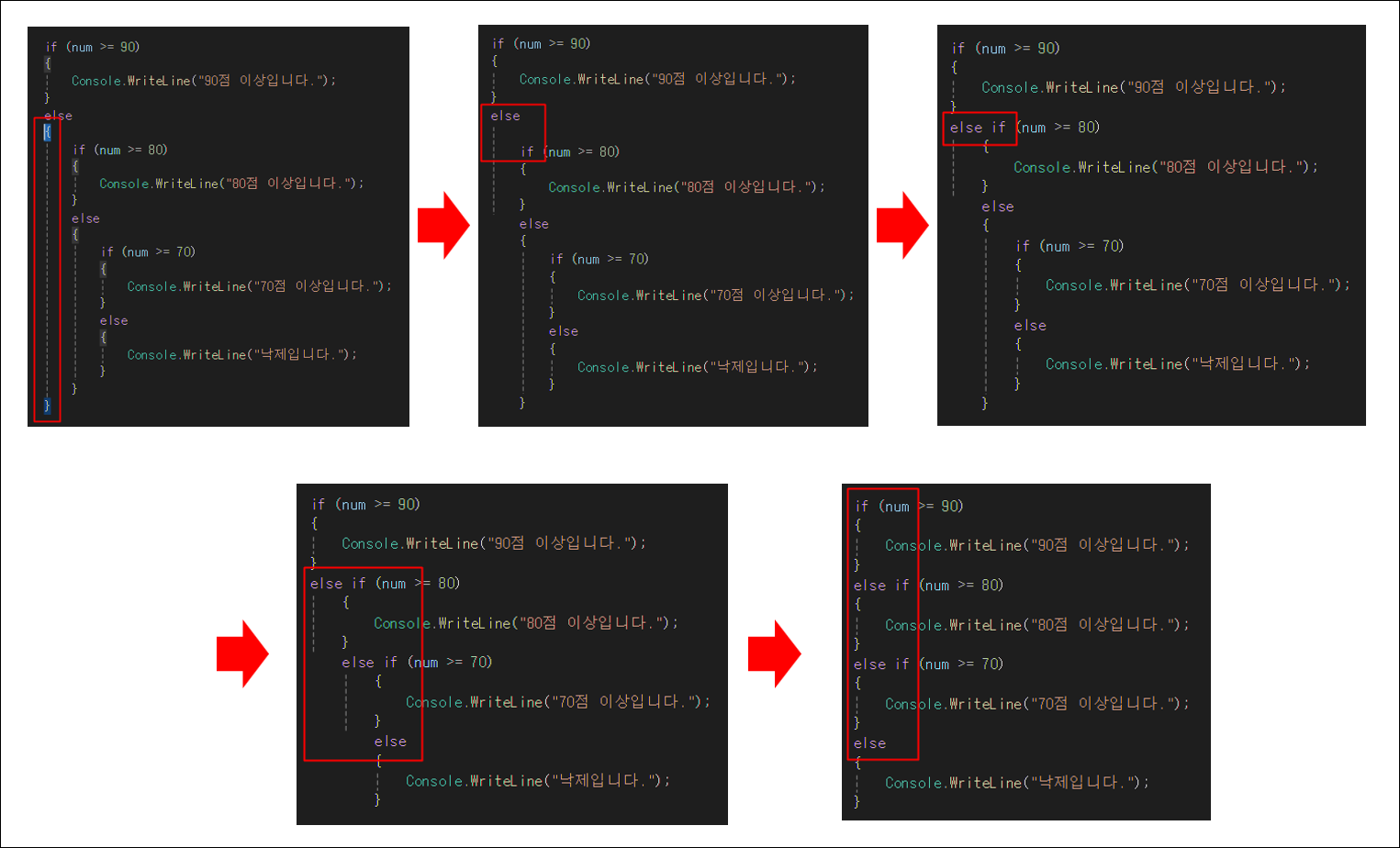
else if는 중괄호가 생략돼서 만들어진 것이다. if문과 else문을 따로 보는 것이 아니라, else문 자체를 하나의 조건문으로 인식하기 때문에 구조상 단일 실행문이다.
switch case
switch case는 if else와 같다. 마지막에 else의 역할을 하는 default는 생략 가능하다.
목차를 찾듯이 맞는 값을 찾아서 해당 위치부터 실행한다. break를 만나면 밖으로 빠져나온다.
case는 일종의 경우의 수이다. 경우의 수가 적고 이에 따른 행동을 나눌 때와 구분이 명확할 때 사용하기 좋다.
case에는 범위를 지정할 수는 없고, 단일 값만 지정할 수 있다.
switch (num)
{
case 10:
case 9:
Console.WriteLine("9 이상입니다.");
break;
case 8:
Console.WriteLine("8 이상입니다.");
break;
default:
Console.WriteLine("7 이하입니다.");
break;
}다른 조건에서 중복된 값을 주고 싶다면 실행 코드 작성 없이 그냥 case 10;처럼 조건만 써도 된다.
3항 연산자
(조건식) ? 참일 경우 값 : 거짓일 경우 값;
string result = (num >= 10) ? "10 이상입니다.": "10 이하입니다.";if else와 같은 결과를 가져온다. 한 줄로 나타낼 수 있어 간단하다.
[ 반복문 ]
2024.04.13 - [Coding/C#] - C# 반복문 for, while, do while, break, continue
반복문에 대한 기초적인 내용은 위 게시글에서도 확인할 수 있다.
소괄호에는 (반복이 이루어지는) 조건이, 중괄호에는 (행동을 실행하라는) 명령이 들어간다.
for문
for (초기화; 조건; 증감)
{
실행 내용
}범위가 명확할 때 사용한다. 반복 횟수와 조건을 직관적으로 볼 수 있다. for (;;)는 무한루프이다.
for문 내에서는 주로 i, j, k를 사용한다.
while문
while (조건)
{
실행 내용
}
조건이 중요시될 때 사용한다. 코드가 간결하다는 장점이 있다. while (true)는 무한루프이다.
do while
do
{
무조건 최초 1회 실행
}
while (조건)
{
조건에 일치하면 실행
}한 번 무조건 실행하고 조건식 검사 후 실행한다.
foreach
foreach (자료형 변수 in 배열/컬렉션)
{
실행 내용
}배열이나 컬렉션에 있는 모든 요소들에 대해 반복적으로 실행한다. 배열/컬렉션에서 요소를 하나씩 꺼내서 사용한다.
중첩반복문
for(초기화; 조건; 증감)
{
for(초기화; 조건; 증감)
{
실행 내용
}
}2차원으로 된 for문 안에 또 for문이 있는 형태다.
break, continue
break: 실행하고 있던 반복문을 중지하고 빠져나온다.
continue: 현재 반복을 무시하고 다음 반복으로 넘어간다.
[ 회고 ]
전반적으로 기초적인 구성이나 작동 방식에 대해서는 사전 캠프 때 공부했었지만, 좀 더 구체적인 작동 원리에 대해 알 수 있었다.
특히 메서드의 구조는 void의 역할에 대해서 알 수 있었다. 처음에는 그냥 계속 들어가 있으니까 눈치로 넣었는데, 이제는 그 역할과 기능을 제대로 알고 코드를 짤 수 있을 것 같다.
'Coding > C#' 카테고리의 다른 글
| [내일배움캠프 9일차 TIL] Txt 게임 만들기 (1) | 2024.04.25 |
|---|---|
| [내일배움캠프 8일차 TIL] 비트 연산자, 시프트 연산, 단축 평가, 비트 플래그, 2진법 (0) | 2024.04.24 |
| [내일배움캠프 6일차 TIL] C#, 객체 지향, 변수, 자료형, 형변환 (0) | 2024.04.22 |
| C# 배열 생성 및 데이터 저장, 접근, 배열 리터럴, 인덱스 (0) | 2024.04.13 |
| C# 반복문 연습 문제 (0) | 2024.04.13 |
[ 문자열 처리 메서드 ]
문자열 생성
string str = new string('s', 7);
Console.WriteLine(str);
//출력결과
sssssssnew 키워드를 사용해서 char 문자와 개수를 지정하면 생성할 수 있다.
분할
string str = "Hello, World!";
string[] split = str.Split(", ");
Console.WriteLine(split[0]);
Console.WriteLine(split[1]);
//출력결과
Hello
World!Split()은 괄호 안의 값을 기준으로 나누는 것이다.
※ 주의할 점
ⓛ 나눈 값을 할당할 변수는 대괄호를 붙여서 배열로 생성해야 한다.
② 출력할 때 나눈 값들을 보고 싶다면 인덱싱을 이용해야 한다.
③ 나누는 기준이 되는 문자가 1개라면 ' ', 2개 이상이라면 " "를 사용한다.
대체
string str = "Hello, World!";
string replace = str.Replace("World", "Seoyeong");
Console.WriteLine(replace);
//출력결과
Hello, Seoyeong!Replace() 함수를 사용해서 앞의 값을 뒤의 값으로 바꿀 수 있다.
검색
string str = "Hello, World!";
int index = str.IndexOf("World");
Console.WriteLine(index);
//출력결과
7IndexOf() 함수는 입력한 값이 맨 처음으로 나오는 인덱스 값을 반환한다.
0부터 세기 시작해서 특수문자, 띄어쓰기 모두 포함한다. World가 처음으로 등장하는 위치는 인덱스 7에 위치라서 7을 출력한다.
변환
1) 숫자 → 문자
int num = 55;
string str = num.ToString();
Console.WriteLine(str);
Console.WriteLine(str.GetType());
//출력결과
55
System.String변수명.ToString()을 사용하면 숫자 타입을 문자열로 바꿀 수 있다. GetType()을 이용해서 타입을 확인했을 때, String 타입인 것을 볼 수 있다. int 타입 외에도 다른 타입도 문자열로 바꿀 수 있다.
2) 문자 → 숫자
string str = "100";
int num = int.Parse(str);
Console.WriteLine(num);
Console.WriteLine(num.GetType());
//출력결과
100
System.Int32int.Parse()를 활용하면 숫자 형태의 문자열을 int 타입으로 변환할 수 있다. GetType()을 이용해서 타입을 확인했을 때, Int 타입인 것을 볼 수 있다.
int 외에도 다른 float, long 등 숫자값을 갖는 다른 타입으로도 변환할 수 있다. 하지만 문자열에서의 숫자가 실수라면, 정수로 변환할 수 없다. 예를 들어 str에 "100.343"과 같은 실수 값이 들어있었다면, int로 변환할 수 없다. 대신 float를 사용해야 한다.
포맷팅
1) 문자열 형식화
string name = "김서영";
int age = 22;
string sentence = string.Format("제 이름은 {0}이고, 나이는 {1}살 입니다.", name, age);
Console.WriteLine(sentence);
//출력결과
제 이름은 김서영이고, 나이는 22살 입니다.자료형.Format("문장~ {인덱스} ", 변수명)의 형태이다. 문자열 안에 중괄호와 인덱스 번호를 쓰고, 뒤에 불러오려는 변수명을 입력한다. 위 코드에서 인덱스 0은 name 변수이고, 인덱스 1은 age 변수이다.
2) 문자열 보간
string name = "김서영";
int age = 22;
string sentence = $"제 이름은 {name}이고, 나이는 {age}살 입니다.";
Console.WriteLine(sentence);
//출력결과
제 이름은 김서영이고, 나이는 22살 입니다.인덱스를 사용하지 않고, 중괄호 내에 직접적으로 변수명을 입력한다. Format()처럼 함수가 아니기 때문에 소괄호는 삭제하고, 앞에 $ 특수문자를 입력한다.
[ 배열 ]
동일한 자료형의 값들이 연속으로 저장된 구조이다. 인덱스를 이용해서 원하는 요소에 접근이 가능하다.
초기화할 때 선언했던 크기만큼 메모리가 할당되며, 나중에 늘리거나 줄이는 것과 같은 수정이 불가능하다.
1차원 배열
int[] num; //선언
num = new int[3]; //초기화
int[] num = new int[3]; //선언 및 초기화
num[1] = 20; //접근1
age = num[1]; //접근2선언: 자료형[] 배열명;
초기화: 배열명 = new 자료형[크기];
선언 및 초기화: 자료형[] 배열명 = new 자료형[크기];
접근1: 배열명[인덱스] = 값;
접근2: 변수명 = 배열명[인덱스];
int[] num = {10, 20, 30};배열을 선언하자마자 데이터 값을 초기화하려면 중괄호 안에 값을 입력하면 되고, 배열의 크기도 따로 지정하지 않아도 된다.
다차원 배열
int[,] array = new int[3,2]; //3행 2열 2차원 배열 선언 및 초기화
array[0,0] = 1; //요소 할당
array[1,0] = 2;
array[2,0] = 3;
array[0,1] = 4;
array[1,1] = 5;
array[2,1] = 6;
int[,] array = new int[3, 2] { { 1, 2}, { 3, 4 }, { 5, 6 } }; //배열 선언 및 요소 초기화1차원 배열이 여러 개로 묶여 있는 것이다. 행과 열로 이루어져 있으며 2차원과 3차원 배열 등이 있다.
[ 컬렉션 ]
배열과 유사하게 자료를 모아놓은 구조이지만, 크기를 변경할 수 있다.
컬렉션을 사용하기 위해서는 System.Collections.Generic 네임스페이스를 추가해야 하고 다양한 컬렉션이 존재한다.
리스트(List)
List<자료형> 리스트명 = new List<자료형>();리스트는 가변적인 크기를 갖기 때문에 크기를 따로 지정하지 않는다. 따라서 요소들을 셀 때 length 대신 count를 사용한다.
데이터를 추가할 때는 리스트명.Add();를 사용해서 리스트의 끝에 요소를 추가한다. 크기가 정해지지 않았기 때문에 인덱스 없이 바로 데이터 값을 입력하면 된다.
데이터를 제거할 때는 리스트명.Remove();를 사용해서 입력된 특정 요솟값을 제거한다. 또는 이미 추가된 요소 내의 인덱스를 이용해서 제거할 수도 있다.
인덱스는 요소가 추가된 순서대로 할당된다. 요솟값이 제거되면 그에 영향을 받는 일부 인덱스도 변경된다.
딕셔너리(Dictionary)
Dictionary<키_자료형, 값_자료형> 딕셔너리명 = new Dictionary<키_자료형, 값_자료형>();키(key)와 값(value)의 쌍이 저장된 구조이다. 딕셔너리에서는 중복된 키를 가질 수 없다.
딕셔너리명.Add(키, 값);를 이용해서 데이터를 추가하고, 딕셔너리명.Remove(키);를 이용해서 데이터를 제거할 수 있다.
딕셔너리의 모든 키-값 쌍을 불러오려면 KeyValuePare<키_자료형, 값_자료형>을 사용한다.
스택(Stack)
Stack<자료형> 스택명 = new Stack<자료형>();후입선출의 구조를 가지고 있다. 아래에서부터 위로 데이터를 쌓는다. 데이터를 뺄 때는 위에서부터, 즉 나중에 들어온 데이터부터 빼낸다.
데이터를 추가할 때는 Push() 함수를 사용하고, Pop() 함수를 이용해서 데이터를 뺄 때는 제일 나중에 추가된 데이터가 출력된다.
큐(Queue)
Queue<자료형> 큐명 = new Queue<자료형>();선입선출의 구조를 가지고 있다. 데이터가 추가된 순서대로 처리된다.
데이터를 추가할 때는 EnQueue() 함수를 사용하고, 데이터를 뺄 때는 Dequeue() 함수를 사용하며 제일 먼저 들어간 데이터가 가장 먼저 나온다.
해시셋(HashSet)
HashSet<자료형> 해시셋명 = new HashSet<자료형>();리스트와 유사하지만 중복되지 않은 요소들로 구성되어 있다.
그렇다면 배열 대신 리스트를 사용하면 되는 것이 아닌가?
리스트는 배열보다 메모리를 더 많이 사용한다. 그리고 인덱싱이 불가능하기 때문에 데이터를 접근하는 데 시간이 더 소요되고, 리스트는 코드가 더 길어지기 때문에 가독성과 유지보수가 어려워진다.
따라서 배열과 리스트 중 사용할 데이터 구조를 선택할 때, 데이터 크기와 사용 목적을 고려하여 적절한 것으로 선택해야 한다.
[ 메서드 ]
개념
접근제한자 자료형 변수명 () {}일련의 코드들을 하나로 묶어놓은 집합이다. 괄호 유무가 함수를 결정한다. 소괄호는 반드시 있어야 하고, 중괄호는 한 줄이면 생략 가능하다.
- 소괄호: 값을 받는 역할(입력받을 데이터)
- 중괄호: 받은 값으로 연산을 하는 역할(실제 로직)
자료형은 반환값의 타입을 의미한다. int라면 정수형 값을 반환한다. void는 반환값이 없어서 아무것도 반환하지 않는다.
기본적으로 int, float와 같은 자료형은 반환값이 있기 때문에 return을 사용해야 하며, 없으면 에러가 발생한다.
하지만 void는 반환값이 없기 때문에 return이 없어도 된다. void에서의 return은 따로 반환값이 있는 게 아니라, 그 즉시 함수가 종료되면서 밑의 로직이 더 이상 실행되지 않는 것이다. 함수를 호출했던 위치로 돌아가서 그다음 줄을 실행한다.
return 값으로 클래스도 반환할 수 있다. 클래스를 반환하는 경우에는 해당 클래스 내부에 있는 코드들도 전부 가져온다.
반환 값이 있으면 외부에서 그 값을 받아서 활용할 수 있다.
public으로 변수에 직접 접근할 수 있지 않나?
그 방법을 지양하는 이유는 보안 상의 문제와, 여러 곳에서 해당 변수를 동시에 사용할 경우 적시에 원하는 값을 못 가져올 수 있기 때문이다.
메서드를 이용해서 반복되는 코드를 다시 작성하지 않아도 되고, 코드의 관리와 유지보수가 편리해진다. 또한 메서드 단위로 행동을 정의하고 메서드 이름을 입력함으로써 전체 코드 구조를 이해하기 쉬워진다.
메서드 오버로딩
void print(string name);
void print(int age);메서드 오버로딩은 메서드명은 같지만, 매개변수의 개수, 타입, 순서가 다른 것이다.
메서드 오버로딩을 할 때는 매개변수만 다르면 서로 다른 메서드로 인식을 하며, 반환값 타입은 고려하지 않는다.
재귀 호출
static void Main(string[] args)
{
CountUp(20);
}
static void CountUp(int n)
{
if (n >= 22)
{
Console.WriteLine("Finish");
}
else
{
Console.WriteLine(n);
CountUp(n + 1);
}
}
//출력결과
20
21
Finish재귀 호출은 메서드가 자기 자신을 호출하는 것이다. 재귀 호출을 하면 호출 스택에 메서드를 쌓고, 반환될 때 쌓인 메서드를 제거해서 호출 됐던 곳으로 다시 돌아간다. 자칫 무한 루프를 발생시킬 수 있으므로 주의해야 한다.
[ 구조체 ]
static void Main(string[] args)
{
Coffee today;
today.menu = "캬라멜마끼아또";
today.count = 3;
today.Print();
}
struct Coffee
{
public string menu;
public int count;
public void Print()
{
Console.WriteLine($"오늘은 {menu}를 {count}잔 마셨습니다.");
}
}
//출력결과
오늘은 캬라멜마끼아또를 3잔 마셨습니다.구조체는 사용자가 정의한 일련의 코드 집합으로, struct 키워드를 이용해서 생성한다.
- 멤버 변수: 필드
- 멤버 함수: 메서드
구조체는 구조체명 변수명;으로 변수를 선언하고, 이 변수에 접근함으로써 구조체 내의 코드를 실행한다.
접근할 때에는 변수명.필드명 = 값; 또는 변수명.메서드명();으로 호출할 수 있다.
[조건문]
2024.04.03 - [Coding/C#] - C# 조건문 if, else if, else, switch case, 조건부 논리 연산자
조건문에 대한 기초적인 내용은 위 게시글에서도 확인할 수 있다.
if문
if문은 조건이 많이 붙을 때 사용하기 좋다.
else는 조건을 만족하지 않은 모든 경우에 실행되기 때문에, 조건을 작성하지 않는다
else if는 중괄호가 생략돼서 만들어진 것이다. if문과 else문을 따로 보는 것이 아니라, else문 자체를 하나의 조건문으로 인식하기 때문에 구조상 단일 실행문이다.
switch case
switch case는 if else와 같다. 마지막에 else의 역할을 하는 default는 생략 가능하다.
목차를 찾듯이 맞는 값을 찾아서 해당 위치부터 실행한다. break를 만나면 밖으로 빠져나온다.
case는 일종의 경우의 수이다. 경우의 수가 적고 이에 따른 행동을 나눌 때와 구분이 명확할 때 사용하기 좋다.
case에는 범위를 지정할 수는 없고, 단일 값만 지정할 수 있다.
switch (num)
{
case 10:
case 9:
Console.WriteLine("9 이상입니다.");
break;
case 8:
Console.WriteLine("8 이상입니다.");
break;
default:
Console.WriteLine("7 이하입니다.");
break;
}다른 조건에서 중복된 값을 주고 싶다면 실행 코드 작성 없이 그냥 case 10;처럼 조건만 써도 된다.
3항 연산자
(조건식) ? 참일 경우 값 : 거짓일 경우 값;
string result = (num >= 10) ? "10 이상입니다.": "10 이하입니다.";if else와 같은 결과를 가져온다. 한 줄로 나타낼 수 있어 간단하다.
[ 반복문 ]
2024.04.13 - [Coding/C#] - C# 반복문 for, while, do while, break, continue
반복문에 대한 기초적인 내용은 위 게시글에서도 확인할 수 있다.
소괄호에는 (반복이 이루어지는) 조건이, 중괄호에는 (행동을 실행하라는) 명령이 들어간다.
for문
for (초기화; 조건; 증감)
{
실행 내용
}범위가 명확할 때 사용한다. 반복 횟수와 조건을 직관적으로 볼 수 있다. for (;;)는 무한루프이다.
for문 내에서는 주로 i, j, k를 사용한다.
while문
while (조건)
{
실행 내용
}
조건이 중요시될 때 사용한다. 코드가 간결하다는 장점이 있다. while (true)는 무한루프이다.
do while
do
{
무조건 최초 1회 실행
}
while (조건)
{
조건에 일치하면 실행
}한 번 무조건 실행하고 조건식 검사 후 실행한다.
foreach
foreach (자료형 변수 in 배열/컬렉션)
{
실행 내용
}배열이나 컬렉션에 있는 모든 요소들에 대해 반복적으로 실행한다. 배열/컬렉션에서 요소를 하나씩 꺼내서 사용한다.
중첩반복문
for(초기화; 조건; 증감)
{
for(초기화; 조건; 증감)
{
실행 내용
}
}2차원으로 된 for문 안에 또 for문이 있는 형태다.
break, continue
break: 실행하고 있던 반복문을 중지하고 빠져나온다.
continue: 현재 반복을 무시하고 다음 반복으로 넘어간다.
[ 회고 ]
전반적으로 기초적인 구성이나 작동 방식에 대해서는 사전 캠프 때 공부했었지만, 좀 더 구체적인 작동 원리에 대해 알 수 있었다.
특히 메서드의 구조는 void의 역할에 대해서 알 수 있었다. 처음에는 그냥 계속 들어가 있으니까 눈치로 넣었는데, 이제는 그 역할과 기능을 제대로 알고 코드를 짤 수 있을 것 같다.
'Coding > C#' 카테고리의 다른 글
| [내일배움캠프 9일차 TIL] Txt 게임 만들기 (1) | 2024.04.25 |
|---|---|
| [내일배움캠프 8일차 TIL] 비트 연산자, 시프트 연산, 단축 평가, 비트 플래그, 2진법 (0) | 2024.04.24 |
| [내일배움캠프 6일차 TIL] C#, 객체 지향, 변수, 자료형, 형변환 (0) | 2024.04.22 |
| C# 배열 생성 및 데이터 저장, 접근, 배열 리터럴, 인덱스 (0) | 2024.04.13 |
| C# 반복문 연습 문제 (0) | 2024.04.13 |